
New Malware Families Signal LLMs Now Require System-Level Threat Monitoring
Google's threat intelligence team has documented operationalized malware families that weaponize LLMs during execution, confirming what security researchers have long warned: AI applications face a class of threats that traditional security tools cannot detect. A convergence of industry reports in early 2026 outlines what a credible monitoring posture now requires. With 40% of enterprise applications projected to integrate AI agents by end of 2026, the attack surface is expanding faster than most security programs can track.
What Happened
In February 2026, Google's Threat Intelligence Group (GTIG) published findings documenting a meaningful shift in how threat actors use AI. Rather than using LLMs as research aids or phishing assistants, attackers have now deployed malware families -- designated PROMPTFLUX and PROMPTSTEAL -- that leverage LLMs at runtime to generate obfuscated payloads and evade signature-based detection. The malware dynamically produces malicious scripts using LLMs during execution, a capability that circumvents static analysis tools designed around deterministic code patterns.
This development coincides with Bright Security's 2026 State of LLM Security report and reinforces OWASP's classification of prompt injection as the number one vulnerability in its Top 10 for LLMs. Prompt injection -- where an attacker embeds malicious instructions into inputs that override an LLM's system directives -- can be delivered directly through user interfaces or indirectly through poisoned data sources, databases, or web content that an LLM retrieves as context.
The core problem is architectural: LLMs are probabilistic systems shaped by training data and live context. Unlike a web server that follows deterministic logic, an LLM's behavior varies with input, making its vulnerability surface fundamentally different from traditional application components.
Why It Matters
Traditional application security operates on a model of fixed code paths and known signatures. Firewalls, vulnerability scanners, and static analysis tools work because the software they protect behaves the same way given the same inputs. LLMs do not. A query that produces a safe response in testing may behave differently in production when paired with a different system prompt, a poisoned retrieval source, or an adversarially crafted user message.
This distinction has practical consequences. As the Bright Security report states, effective LLM security "requires moving beyond traditional vulnerability scanning toward comprehensive threat modeling and behavioral monitoring of AI systems operating as active participants in business workflows." The same conclusion appears in guidance from the US Cybersecurity and Strategy Institute and from Datadog's security research team, which notes that "traditional security measures can't capture what happens once an LLM interacts with real users and data."
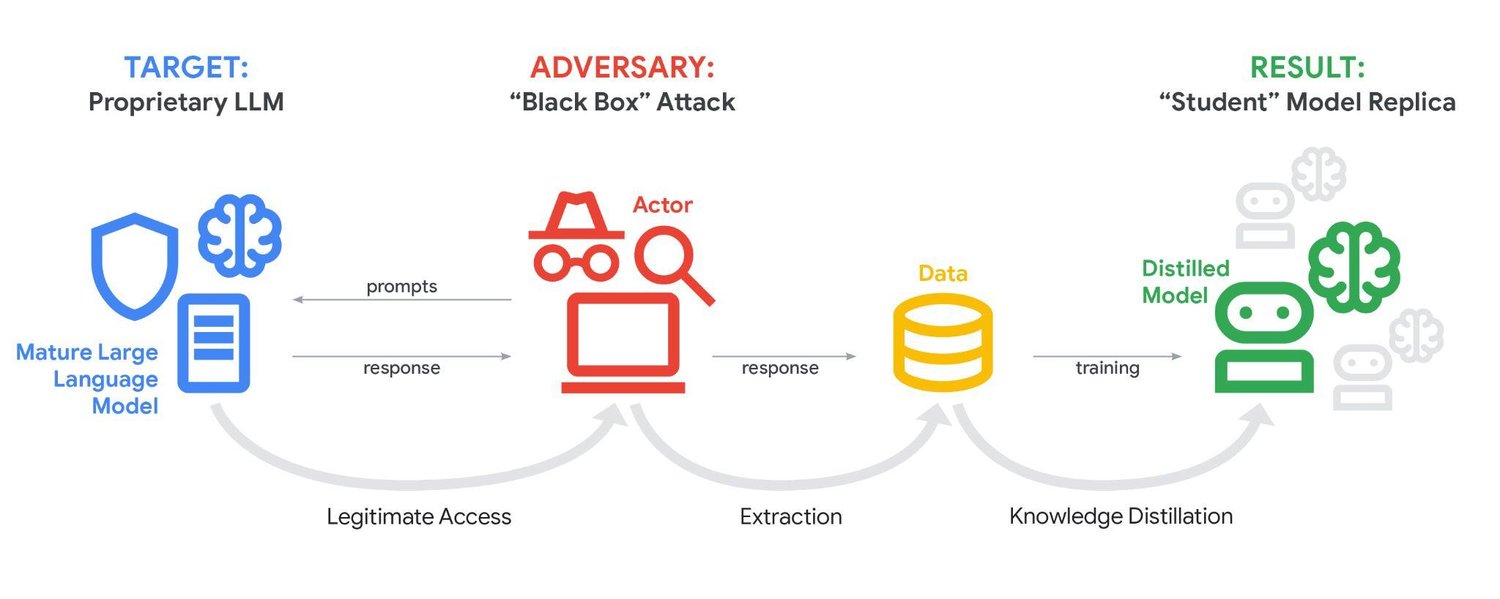
What system-level monitoring now covers is well-defined across the industry. Security teams need visibility into input prompt patterns, LLM outputs, function and tool calls, data access logs, inference latency, token consumption, and resource utilization -- all tracked continuously against behavioral baselines. For applications built on Retrieval-Augmented Generation (RAG) architectures, where LLMs pull live data from external databases to answer queries, monitoring extends further: vector database audit logs, embedding retrieval patterns, and source document validation are required to catch indirect injection attacks and data poisoning attempts. Model extraction attacks -- where adversaries systematically query a production model to replicate its capabilities without direct network access -- require rate limiting, semantic analysis, and canary token detection.
Zero-trust architecture, previously applied to networks and identity systems, is now being extended to LLMs: all inputs are treated as untrusted regardless of source, all outputs are validated before downstream use, and tool access requires continuous authorization verification.
One important complication deserves attention. Research published on arxiv (paper 2410.02916) demonstrates that security guardrails themselves can become an attack vector. Adversarial prompts of approximately 30 characters can trigger safeguards to block 97% of legitimate user requests, creating denial-of-service conditions. Monitoring systems that are too aggressive produce alert fatigue; those that are too permissive miss attacks. Calibration is not a one-time task -- it requires continuous refinement and regular updates as new attack variations emerge.
The market is responding to this gap. The LLM security tools segment is projected to grow at more than 50% compound annual growth rate through 2028, as breach incidents accumulate and compliance requirements under frameworks such as the EU AI Act begin to demand evidence of monitoring controls.
Sources
- T1
- T1
- T1
- T2
Stay informed. The best AI coverage, delivered weekly.